NLP(自然語言處理)是眾多金融科技中較為重要的一項技術,其應用范圍包括信息分類,新聞摘要,輿論情感分析,智能客戶服務,手寫文本識別等。本文主要介紹了中文語境下,NLP在智能客戶服務中的應用。
越來越多的金融企業開始采用人工智能機器人來取代原有的人工客戶服務,尤其在虛擬銀行風起潮湧的今天,金融企業不再有實體網點,一切金融服務均通過網絡雲服務實現。在智能客戶服務應用場景中,通過智能聊天機器人(chatbot)可以為客戶解答問題,完成指令操作如轉賬匯款等。隨著技術與業務的深入結合,客戶幾乎可以通過手機端的自然語音輸入完成所有業務的辦理,人工智能為客戶帶來最好的體驗和便利。智能聊天機器人主要涉及幾方面的技術:語音識別,語義理解,答案生成等。
語音識別
語音識別是利用機器學習,將語音輸入轉化為文本輸出的技術。以開放平台Kaldi實現中文語音轉文本為例,用超過40個小時的語音數據(speech data),采用基於MFCC, LDA+MLLT的DNN(Deep Neural Networks, 深度神經網絡)訓練出一個語音模型(acoustic model),再建立一個超過1萬個中文字符的語言模型(language model),其中2-gram字集用於初始打分,4-gram字集(corpus)用於再打分,用某新聞報刊的新聞文本(超過1.5Gb的字集)可以訓練出一個中文語音識別引擎。為了支持中文語音中混合有英文單詞的情況,可以在中文音集(phone set)裡和英文共用部分輔音,並在音集裡補充英文特有的元音和輔音,這樣可以用同一個語音模型來處理兩種語言,再輔以金融專業領域的語言模型和字集來降低錯字率(WER)。之後,用一個中英字典來將英文和中文對應,可以生成中英混合的n-gram數據用以訓練語言模型,如下圖所示:
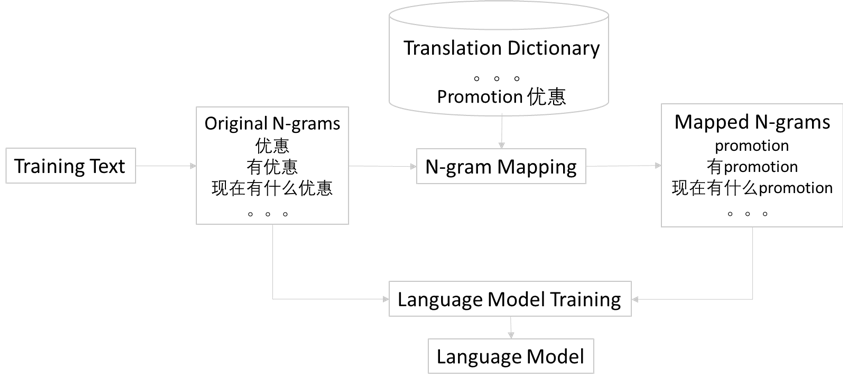
這樣就可以得到一個支持中英混合語言的語音識別引擎。
語義理解
當語音轉化為文字後,chatbot要想辦法理解文字的含義。對於Q&A型的chatbot, 最通常的做法是找到問題中的關鍵字。對於中文文本,在尋找關鍵字之前先要進行分詞,即將一個中文語句分成若干詞組,中文分詞通常采用的技術是基於統計模型的N-gram語言模型分詞方法或基於序列標注的HMM(隱馬爾可夫模型)分詞方法,例如著名的jieba分詞,就是用DAG(有向無環圖)+ Uni-gram的語言模型+ 後向DP(動態規劃)的方式進行的,而對於不在已知詞表中的新文本,jieba采用HMM方法來識別新詞和進行分詞。目前利用大量語料訓練的基於深度神經網絡的序列標注算法在詞性標注、命名實體識別問題上取得了很好的進展,是分詞技術的新趨勢。
完成分詞後,可以根據詞性將較為重要的名詞和動詞抽取出來作為問題關鍵詞,再和chatbot的知識庫中的關鍵詞進行匹配查找,從而定位到相關的答案並輸出答案完成一次Q&A對話。這種關鍵字匹配方法可以快速實現簡單的問答(Q&A),但缺陷也很明顯,比如對同一個問題的不同表述,使得問題關鍵字不同:
1. 我想開個儲蓄賬戶
2. 我想開個儲蓄戶口
兩個問題是同一含義,但賬戶和戶口是不同表達,如果知識庫中的關鍵字是賬戶,那麼簡單的關鍵字匹配方法就不能處理戶口這個問題。為使chatbot系統能將兩者視為同義,則系統需建立一個同義/近義詞表,在進行關鍵字匹配前進行同一化處理。這種補充可以提高chatbot的Q&A正確率,但仍有不能處理的場景,比如:
「除了開戶優惠,有沒有其他優惠?」
從該問題中提取的關鍵詞是開戶,優惠,當系統進行匹配時找到的最合適答案是和開戶優惠相關的:
目前我行針對新開戶客戶有如下優惠。。。
而這個答案恰恰是答非所問。這是關鍵字匹配方法中目前不能很好地處理語意理解的一種情況。
現在有一些新的技術從另外一個角度來處理語義的多樣性問題。Q&A場景中,同一個問題有不同表達方式,對一個已知問題,我們怎麼才能知道其他不同的表達和已知問題樣本是相似呢?Levenshtein Distance是一種簡單易用的方法,通過計算兩個樣本的編輯距離來確定樣本的相似度。而隨著word2vec技術的推出,其也被應用在語句相似度的判斷上。通過word2vec將一個語句中的所有詞(word)轉化為向量(vector),再把所有的向量相加求平均,就可得到一個語句的向量,將兩個語句的向量求夾角余弦值,值越大,則相似性越高。
答案生成
Chatbot答案的生成有幾種方式。一種是已知答案,即針對已知問題已准備好答案,只要將輸入問題與已知問題匹配上,則答案已知,輸出該答案。另一種是將輸入問題放到搜索引擎中尋找排名最前的答案,這種方法的性能完全依賴搜索引擎的性能表現。再一種方法是建立自己的知識圖譜,通過知識圖譜的檢索來生成答案。
Chatbot的會話設計
在chatbot的實際使用中,會遇到這樣的情景,用戶沒有在一個問題中給出所有能定位答案的元素,例如:
現在信用卡有什麼優惠活動?
而銀行的優惠是針對不同信用卡類型的,比如visa卡有優惠,而master卡沒有優惠,要提供准確答案,就需要用戶再提供多一些信息,這時,一次問和答的過程是由一組對話來完成的:
用戶:現在信用卡有什麼優惠活動?
Chatbot:請問您想知道以下那種卡的優惠: visa, master?
用戶:visa卡的。
Chatbot:目前visa卡有如下優惠:。。。
當系統識別到第一個用戶問題時,會在知識圖譜中檢索,當發現當前信息不能匹配答案時,根據圖譜走向獲知缺乏的信息,用缺乏的信息生成問題反問用戶,直到獲取足夠信息定位答案。
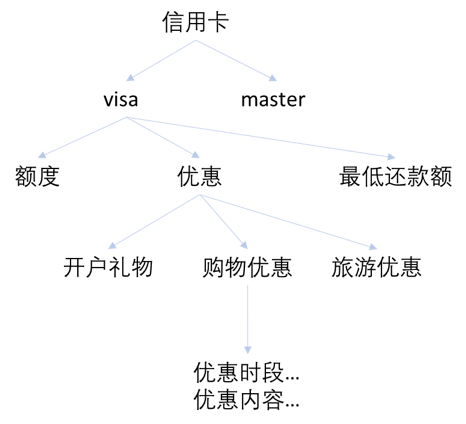
由此可見,對用戶問題的理解是從多個語句中綜合得到的,因此chatbot還需要處理上下文關系,狀態轉移表技術(state transition table)可以用來處理chatbot 在對話中的反應。另外,用戶隨時可以從一個話題跳轉到另一個話題,chatbot需要利用知識圖譜和狀態表來確定一個主題的終結和新主題的確立。
一些chatbot系統中會設計3種應答模式:高信心應答模式,低信心應答模式,全匹配應答模式。當用戶的問題和系統已知問題完全匹配時,系統給出特定答案,這是全匹配應答模式;當用戶的問題和已知問題不完全匹配時,可以根據比較算法的結果找到與用戶問題相似概率最大的已知問題,用其對應的答案作為輸出,這是高信心應答模式;而當比較算法的結果低於設定的閾值時,chatbot可以從事先准備的應答池中隨機挑選一個作為輸出,例如:對不起,您的問題和業務無關,這是低信心應答模式。這種應答設計可以較好的覆蓋應用場景。
Chatbot是多種技術的集成者,可以幫助金融業務做到隨時,隨地,自然語言交互,給客戶帶來輕松自如的服務,這種新的人機交互方式是未來人與互聯網的連接入口,將有越來越多的應用采用這種新技術。