计算机非常擅长使用结构化数据,因此针对大量的数据和表格的处理,它都信手拈来。但是对于人类来说,我们是以非结构化的文字等信息进行交流的。计算机并不擅长处理这些非结构化数据,因此如何让计算机理解人类的语言,一直以来是一大难题。
什么是自然语言处理?与其他领域相比,针对金融领域的自然语言处理有何不同?
NLP本身是人工智能中的一个重要的方向,简单来说,处理自然语言的过程就是让机器去理解人的文本或语言,其中如翻译、语音识别、语义理解、智能问答,知识图谱等都属于NLP的范畴。
自计算机诞生伊始,人类就致力于让机器来理解我们语言。随着人工智能、计算机科学、信息工程、统计学、甚至语言学等学科知识的不断进步,目前NLP已经拥有了大量的商业应用,如机器翻译(Google翻译、有道翻译等)、知识图谱(以Google为代表的搜索引擎)、智能问答(Apple的Siri、亚马逊的Alexa以及各种智能机器人)等等。
但是,金融领域的NLP目前仍处于探索阶段,金融本身是一个专业性很高的领域,很多词汇在金融语境下会产生特殊含义,所有的子问题都会有一个独特的理解方式,而且金融领域衡量处理结果的方式也与其他领域不同。比如针对舆情分析,金融领域要求对市场未来的走势有一定的预见性。
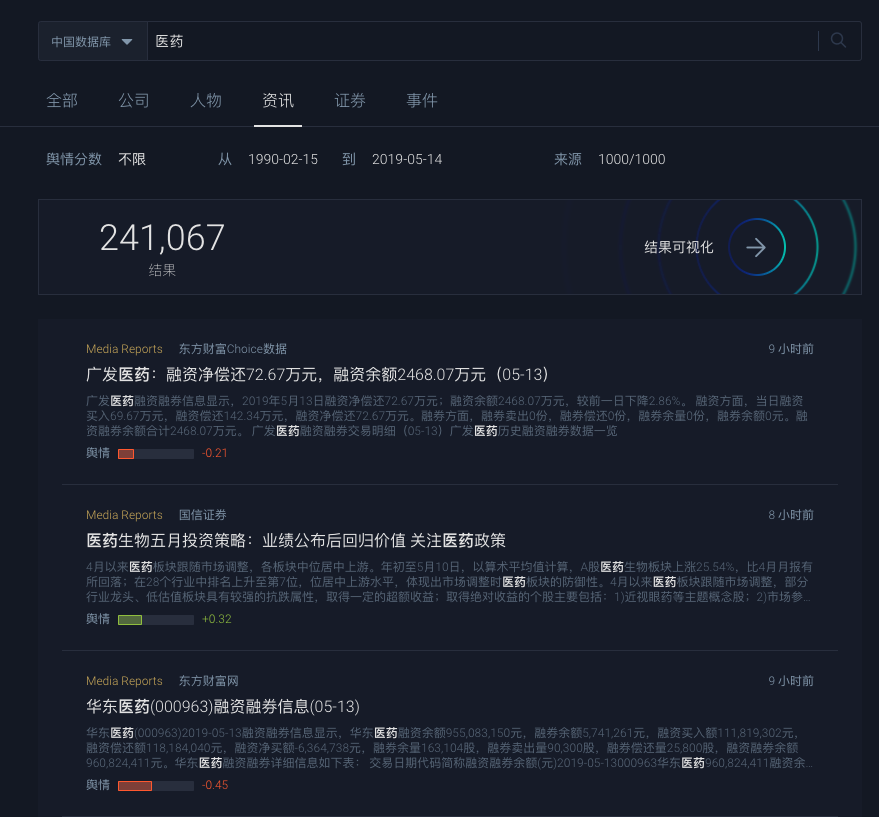
妙盈科技AMI系统中对新闻舆情进行分类与评分处理
因此,金融领域的NLP需要准备特殊的训练数据集,而目前NLP所有方法都是基于大量的数据集基础上,数据集的缺乏也是目前NLP在金融领域所面临的最大问题之一,这也是金融领域高度的专业性与深度导致的。
在妙盈科技,我们应用NLP专注于解决NER、关系提取以及知识图谱的建立。利用已经关联好的其他数据对数据集进行补充,也就是利用知识图谱来弥补训练集的不足。

MioTech AMI - 知识图谱
自然语言处理的发展经历了哪些阶段?遇到了哪些挑战?
NLP的发展进程与人工智能发展的脚步大体相同,都经历了如下的发展阶段:
-
20世纪50 - 80 年代:简单的实现人类掌握的规则,基于人类的经验;
-
20世纪90年代 - 2000年左右:主要基于统计学的原理与方法;
-
2000年之后至今,由于数据的大幅增强、计算力的大幅提升,人们也逐渐开始将如日中天的深度学习方法引入到NLP领域中,在机器翻译、问答系统、自动摘要等方向取得了重大突破。
但同时也应当注意到,NLP目前也仍然面临诸多的挑战。人类的语言非常简练,在很多对话中是省略背景知识的。人类自己是可以很容易地理解这种省略的背景知识,但在NLP的过程中却可能是很大的挑战。
比如“司机,我在前门下车”这句话,当机器不了解具体语境的时候,就难以分清究竟在公交车前门,还是在北京前门站下车。
面向中文与英文的NLP存在哪些不同?中文NLP,特别是在金融领域存在哪些难点,有没有某种算法是最佳的?
从语言本身上来看,英文比中文更直接,利用名词就可以很大程度上判断出一句话的语义。作为表音文字,英文还可以通过语法、时态、词性、词根、词缀、单复数等形式来让机器判断真实意图。
中文是象形文字,没有各种词性的转换,也无法对某个单字进行拆分,因此机器一定要通过上下文语境来判断具体语义。由于中文的特殊性,同一个任务、同一个模型在英文语境的表现一般要比中文好。
中文分词是中文NLP的难点之一。如“结婚的和尚未结婚的”,应该分词为“结婚/的/和/尚未/结婚/的”,还是“结婚/的/和尚/未/结婚/的”,不同的分词方法会产生一定的歧义。再比如,“美国会通过对台售武法案”,我们既可以切分为“美国/会/通过对台售武法案”,又可以切分成“美/国会/通过对台售武法案”。
随着深度学习的普遍使用,中文与英文在语言上的差异也逐渐变成训练数据量上的差异,以往在NLP领域,可供使用的中文数据量比英文数据要少的多,这是目前中文NLP的难点之一。但是随着有越来越多的人投入到中文人工智能以及NLP领域的研究中来,中文数据集不足的问题正在逐年改善。
在金融领域,针对基础性问题,中英文所处的阶段其实大体相同,但是针对如情感分析、市场预测等复杂问题,由于要结合具体的语境以及相应的应用场景,同时要考虑训练的数量级问题,无论是中文还是英文的NLP要走的路都还有很多。
一个强大的NLP系统能够帮助金融机构解决哪些实际问题?
全网舆情监控、产业链分析、让机器帮助金融机构阅读大量新闻。
例如,商业银行希望使用更全面的数据进行企业的信贷风险管理,提前感知企业的潜在风险。目前常规的风险评估方法是根据企业公布的年报,并综合信贷员实地调查的结果进行判断,但是由于企业自身风险报出通常具有滞后性,公开信息覆盖度不高,看到的往往只是冰山一角,因此判断风险的手段十分单一。这也是NLP与人工智能可以发挥作用的地方。
NLP可以对信息进行多维关系的挖掘,评估企业之间的关系,并通过知识图谱直观呈现企业之间的关联,提前设立预警信号,一旦企业关系网内的相关对象出现任意变动,便可根据关系权重,快速地评估对整个关系网的影响程度。

知识图谱在企业信用风险预测中的作用
根据上市公司公开财报进行产业链挖掘是我们对NLP的又一应用。产业链数据以所有A股上市公司财报为原始数据源,根据公开财报中的主营业务构成,提取关键词后输入至预训练的神经网络中,对其进行向量表达。接下来,我们对输入向量进行基于密度的聚类计算,输出不同密度的集群,并最终进行集群命名。
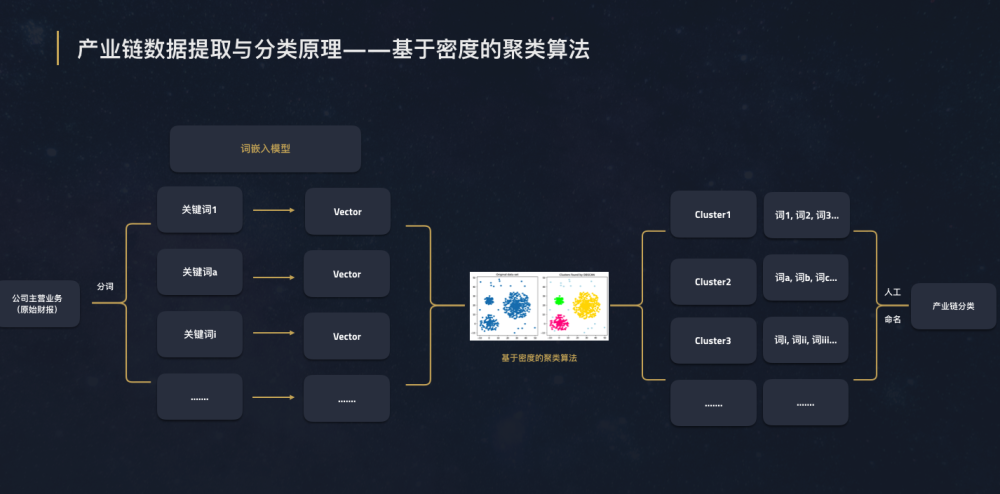
产业链数据提取原理——基于密度的聚类算法
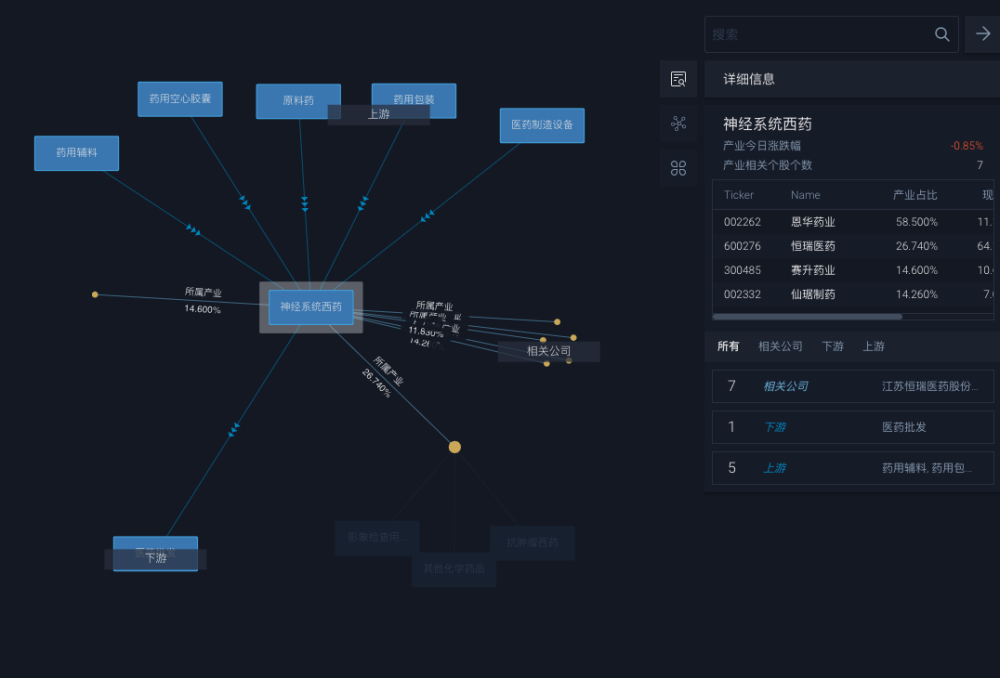
MioTech AMI 产业链数据展示
未来,中文NLP将会有哪些突破?
随着每天产生的数据越来越多,可供机器进行训练的数据集也会不断增多。同时,随着深度学习的发展,算法的不断进步,将不断降低对人类以往经验的依赖度,就像Alpha Go,摆脱人类经验后,它会表现更加出色。
特别是在BERT模型出现后,刷新了很多传统NLP问题的准确程度,甚至在机器阅读理解上,有些模型的准确程度已经全面超越人类。以机器阅读理解为例,今年,人工智能在斯坦福大学阅读理解测试(SQuAD)中击败了人类。根据SQuAD网站上的排行榜显示,截至3月20日,使用的是BERT算法模型的EM得分(精确匹配,提供准确的问题答案)为87.147,排在首位,得分高于人类的86.831分。
从中文角度,NLP将向着深度学习的方向继续发展,随着数据集越来越丰富,针对复杂语义上的关系抽取将会更准确、针对情感识别也将逐渐进步。妙盈科技,作为这一赛道中面向金融领域的人工智能公司,随着NLP算法的发展,我们的核心技术即实体识别与关系提取将会更加准确,提供的应用也将愈发成熟。