NLP(自然语言处理)是众多金融科技中较为重要的一项技术,其应用范围包括信息分类,新闻摘要,舆论情感分析,智能客户服务,手写文本识别等。本文主要介绍了中文语境下,NLP在智能客户服务中的应用。
越来越多的金融企业开始采用人工智能机器人来取代原有的人工客户服务,尤其在虚拟银行风起潮涌的今天,金融企业不再有实体网点,一切金融服务均通过网络云服务实现。在智能客户服务应用场景中,通过智能聊天机器人(chatbot)可以为客户解答问题,完成指令操作如转账汇款等。随着技术与业务的深入结合,客户几乎可以通过手机端的自然语音输入完成所有业务的办理,人工智能为客户带来最好的体验和便利。智能聊天机器人主要涉及几方面的技术:语音识别,语义理解,答案生成等。
语音识别
语音识别是利用机器学习,将语音输入转化为文本输出的技术。以开放平台Kaldi实现中文语音转文本为例,用超过40个小时的语音数据(speech data),采用基于MFCC, LDA+MLLT的DNN(Deep Neural Networks, 深度神经网络)训练出一个语音模型(acoustic model),再建立一个超过1万个中文字符的语言模型(language model),其中2-gram字集用于初始打分,4-gram字集(corpus)用于再打分,用某新闻报刊的新闻文本(超过1.5Gb的字集)可以训练出一个中文语音识别引擎。为了支持中文语音中混合有英文单词的情况,可以在中文音集(phone set)里和英文共用部分辅音,并在音集里补充英文特有的元音和辅音,这样可以用同一个语音模型来处理两种语言,再辅以金融专业领域的语言模型和字集来降低错字率(WER)。之后,用一个中英字典来将英文和中文对应,可以生成中英混合的n-gram数据用以训练语言模型,如下图所示:
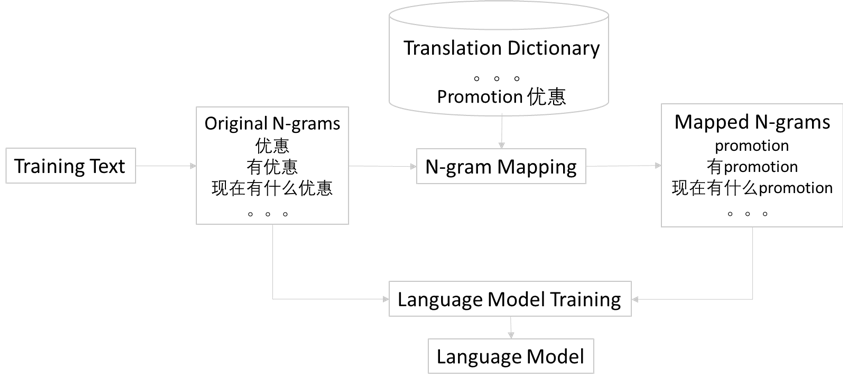
这样就可以得到一个支持中英混合语言的语音识别引擎。
语义理解
当语音转化为文字后,chatbot要想办法理解文字的含义。对于Q&A型的chatbot, 最通常的做法是找到问题中的关键字。对于中文文本,在寻找关键字之前先要进行分词,即将一个中文语句分成若干词组,中文分词通常采用的技术是基于统计模型的N-gram语言模型分词方法或基于序列标注的HMM(隐马尔可夫模型)分词方法,例如著名的jieba分词,就是用DAG(有向无环图)+ Uni-gram的语言模型+ 后向DP(动态规划)的方式进行的,而对于不在已知词表中的新文本,jieba采用HMM方法来识别新词和进行分词。目前利用大量语料训练的基于深度神经网络的序列标注算法在词性标注、命名实体识别问题上取得了很好的进展,是分词技术的新趋势。
完成分词后,可以根据词性将较为重要的名词和动词抽取出来作为问题关键词,再和chatbot的知识库中的关键词进行匹配查找,从而定位到相关的答案并输出答案完成一次Q&A对话。这种关键字匹配方法可以快速实现简单的问答(Q&A),但缺陷也很明显,比如对同一个问题的不同表述,使得问题关键字不同:
1. 我想开个储蓄账户
2. 我想开个储蓄户口
两个问题是同一含义,但账户和户口是不同表达,如果知识库中的关键字是账户,那么简单的关键字匹配方法就不能处理户口这个问题。为使chatbot系统能将两者视为同义,则系统需建立一个同义/近义词表,在进行关键字匹配前进行同一化处理。这种补充可以提高chatbot的Q&A正确率,但仍有不能处理的场景,比如:
“除了开户优惠,有没有其他优惠?”
从该问题中提取的关键词是开户,优惠,当系统进行匹配时找到的最合适答案是和开户优惠相关的:
目前我行针对新开户客户有如下优惠。。。
而这个答案恰恰是答非所问。这是关键字匹配方法中目前不能很好地处理语意理解的一种情况。
现在有一些新的技术从另外一个角度来处理语义的多样性问题。Q&A场景中,同一个问题有不同表达方式,对一个已知问题,我们怎么才能知道其他不同的表达和已知问题样本是相似呢?Levenshtein Distance是一种简单易用的方法,通过计算两个样本的编辑距离来确定样本的相似度。而随着word2vec技术的推出,其也被应用在语句相似度的判断上。通过word2vec将一个语句中的所有词(word)转化为向量(vector),再把所有的向量相加求平均,就可得到一个语句的向量,将两个语句的向量求夹角余弦值,值越大,则相似性越高。
答案生成
Chatbot答案的生成有几种方式。一种是已知答案,即针对已知问题已准备好答案,只要将输入问题与已知问题匹配上,则答案已知,输出该答案。另一种是将输入问题放到搜索引擎中寻找排名最前的答案,这种方法的性能完全依赖搜索引擎的性能表现。再一种方法是建立自己的知识图谱,通过知识图谱的检索来生成答案。
Chatbot的会话设计
在chatbot的实际使用中,会遇到这样的情景,用户没有在一个问题中给出所有能定位答案的元素,例如:
现在信用卡有什么优惠活动?
而银行的优惠是针对不同信用卡类型的,比如visa卡有优惠,而master卡没有优惠,要提供准确答案,就需要用户再提供多一些信息,这时,一次问和答的过程是由一组对话来完成的:
用户:现在信用卡有什么优惠活动?
Chatbot:请问您想知道以下那种卡的优惠: visa, master?
用户:visa卡的。
Chatbot:目前visa卡有如下优惠:。。。
当系统识别到第一个用户问题时,会在知识图谱中检索,当发现当前信息不能匹配答案时,根据图谱走向获知缺乏的信息,用缺乏的信息生成问题反问用户,直到获取足够信息定位答案。
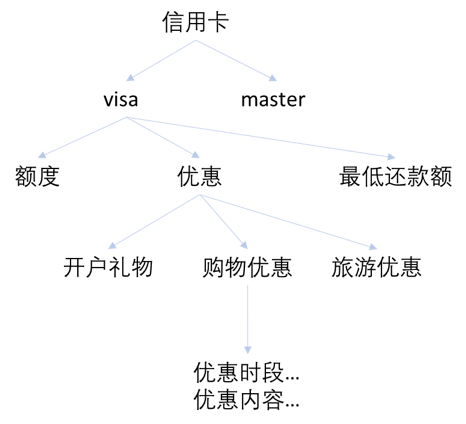
由此可见,对用户问题的理解是从多个语句中综合得到的,因此chatbot还需要处理上下文关系,状态转移表技术(state transition table)可以用来处理chatbot 在对话中的反应。另外,用户随时可以从一个话题跳转到另一个话题,chatbot需要利用知识图谱和状态表来确定一个主题的终结和新主题的确立。
一些chatbot系统中会设计3种应答模式:高信心应答模式,低信心应答模式,全匹配应答模式。当用户的问题和系统已知问题完全匹配时,系统给出特定答案,这是全匹配应答模式;当用户的问题和已知问题不完全匹配时,可以根据比较算法的结果找到与用户问题相似概率最大的已知问题,用其对应的答案作为输出,这是高信心应答模式;而当比较算法的结果低于设定的阈值时,chatbot可以从事先准备的应答池中随机挑选一个作为输出,例如:对不起,您的问题和业务无关,这是低信心应答模式。这种应答设计可以较好的覆盖应用场景。
Chatbot是多种技术的集成者,可以帮助金融业务做到随时,随地,自然语言交互,给客户带来轻松自如的服务,这种新的人机交互方式是未来人与互联网的连接入口,将有越来越多的应用采用这种新技术。